
Symfony ExpressionLanguage : Comment utiliser ce composant ?
Le composant Symfony ExpressionLanguage : qu'est-ce que c'est ? Quand et comment l'utiliser ? Comment créer des expressions lors de cas plus complexes ?

Les 10 & 11 octobre a eu lieu le mythique Forum PHP 2024 organisé par l'AFUP, qui a élu domicile depuis quelques années maintenant à Disneyland Paris (dans le très classe Hôtel New York).
J'ai personnellement assisté aux conférences du 2ème jour, et si parfois le choix à faire entre 2 conférences était difficile, celles que j'ai pu voir étaient passionnantes.
Alors, si vous voulez un petit résumé concis et efficace des conférences qui m'ont le plus marqué, vous êtes au bon endroit !
![]()
Nous allons plonger dans 3 conférences. La première est générale tandis que les 2 suivantes sont plus techniques. Prêts ? C'est parti !
Je suis allé à cette première conférence en pensant naïvement qu'on allait nous servir le discours réchauffé de l'importance de connaître le cycle de vie de nos requêtes HTTP.
Mais c'est mal connaître Pascal Martin, qui à chaque fois fait mouche lors de ses talks grâce à son grand talent de speaker, et son story-telling léché. Pascal est parti d'une question qu'il adore poser en entretien technique : "Quel est le chemin d'une requête HTTP ?" et s'est rendu compte que les réponses étaient très différentes selon les profils.
Et pour autant, il n'y a pas qu'une seule bonne réponse, bien qu'il existe un début de réponse classique et très cartésien :
Ma requête interroge un serveur DNS pour la résolution de mon URL en adresse IP, cette résolution va se transmettre de serveur en serveur jusqu'à atterrir au niveau du serveur que je vise, etc...
Mais même là, on pourrait rentrer dans de nombreux détails. Parler du système DNS du FAI, du cache DNS, des CDN, ou encore se poser la question de ce que transporte notre requête; quels headers ? Un simple GET, un POST ? Quelles couches vais-je traverser (les fameuses couches IP, TCP, TLS qui me ramènent aux souvenirs pas si lointain des bancs de la fac).
Pour chaque étape de ce chemin, on pourrait se perdre dans une multitude de sous-étapes. Très rapidement, on se retrouve devant une liste vertigineuse de concepts, et on se demande...
Question
Et pour chaque étape de se soucier de la sécurité, de la performance, etc... ?!! --> crise d'angoisse
Et c'est à ce moment que Pascal nous rassure et nous explique là où il veut en venir : qu'il faut se rappeler que nos métiers sont complexes, et que nous ne pouvons pas tout savoir.
Il est normal d'avoir besoin d'être soutenu par une équipe aux compétences variées, des développeurs certes, mais également des PO, des QA, des DevOps (et oui, MÊME EUX).
Il faut savoir rester humble dans son ignorance et sa connaissance partielle de certains sujets, et se souvenir du profil en T, comme illustré ci-dessous.
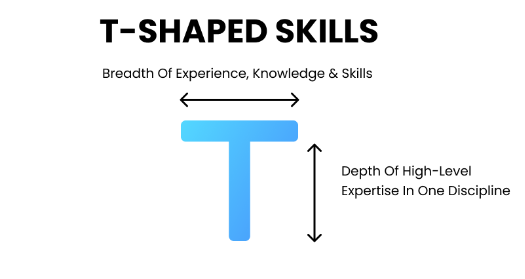
Sur ce schéma, le T représente chacun d'entre nous. La base horizontale du T exprime l'étendue de nos connaissances : C'est un peu notre culture générale de développeur. On ne maîtrise pas tout ce qui s'y trouve, mais on s'y est au moins intéressé un jour.
Et puis il y a la barre verticale du T, qui désigne les domaines où nous nous spécialisons. Il s'agit de ce que nous faisons au quotidien, ce qui nous passionne et que nous maîtrisons sur le bout des doigts. Cette barre s'affine et se solidifie au fil du temps, de notre expérience et de nos apprentissages.
C'est donc à la fois une belle leçon d'humilité, mais également une consolation pour tous ceux qui sont sujets au syndrome de l'imposteur.
Important
En résumé
Pour la deuxième conférence de la journée, il est temps de rejoindre Baptiste Langlade pour sa présentation sur l'ORM Formal.
Le constat de Baptiste est le suivant : l'écosystème PHP a beaucoup évolué ces dernières années, mais peut-être trop rapidement par rapport aux ORMs aujourd'hui à notre disposition.
Pour rappel, il en existe principalement deux styles : les ORMs Active Record (Eloquent), et les Data Mapper (Doctrine). Le but de ces ORMs est de nous fournir une interface objet pour la manipulation de leur représentation SQL.
Prenant l'exemple de Doctrine, Baptiste attire notre attention sur le fait que ce dernier garde en mémoire toutes les entités chargées (coûteux en performance), et que l'on doit ajouter des propriétés id partout sur nos objets, ce qui est un non-sens d'un point de vue métier, en particulier à l'ère du Domain Driven Design.
De plus, la programmation fonctionnelle est une pratique qui est de plus en plus populaire de nos jours, et Formal serait un ORM qui en épouse tous les principes.
Pour commencer avec Formal, il faut partir d'un Aggrégat. C'est cet objet parent qui sera la référence et l'identité de ses sous objets.
Prenons l'exemple d'une voiture et de sa carte grise, voilà comment on pourrait écrire nos entités avec Formal :
use Formal\ORM\Id;
final readonly class Voiture
{
/** @param Id<self> $id */
public function __construct(
private Id $id,
private CarteGrise $carteGrise,
) {
}
}
final readonly class CarteGrise
{
public function __construct(
private string $immatriculation,
private string $proprietaire,
private string $adresse,
) {
}
}
$carteGrise = new CarteGrise('aa-123-bb', 'John Doe', 'Somewhereville');
$voiture1 = new Voiture(
Id::new(Voiture::class),
$carteGrise,
);
$voiture2 = new Voiture(
Id::new(Voiture::class),
$carteGrise,
);On observe plusieurs choses :
Voiture. C'est elle seule qui porte l'id, et qui possède ses relations.CarteGrise ne possède pas d'id car on considère qu'elle appartient à l'aggrégat.CarteGrise ne possède donc aucune référence vers Voiture, ce qui empêche tout risque de dépendance circulaire.Id de Formal pour construire explicitement un nouvel id pour chaque nouvelle Voiture.$carteGrise ne possédant pas d'id propre, on peut l'assigner à deux voitures différentes : il s'agira bien en base de deux lignes différentes.Important
Avec Formal, les entités sont immuables, afin de s'assurer que toute donnée n'appartient qu'à un seul Aggrégat. Pour mettre à jour un Aggrégat il faut donc en créer une copie, avec les données modifiées. Formal se chargera de calculer les diffs lors de la mise à jour.
Il nous faut ensuite enregistrer nos voitures en base. Pour cela, Formal choisit une formulation explicite :
$repository = $manager->repository(Voiture::class);
$manager->transactional(
static function() use ($repository) {
$voiture = ...;
$voiture = $voiture->changerAdresse('nouvelle adresse');
$repository->put($voiture);
return ...;
},
);Toute cette logique doit se passer dans une transaction. Notons qu'il n'y a pas besoin de créer manuellement un Id comme montré plus haut : Formal en créera un automatiquement s'il détecte que votre objet n'en possède pas. Autrement, il fera une mise à jour de votre objet.
C'est la fonction put qui sauvegarde en base de donnée notre objet. Avec Doctrine, on utiliserait flush pour insérer / mettre à jour tous les objets présents dans la mémoire de l'EntityManager.
Or avec Formal, pour éviter tout problème de fuite mémoire, l'ORM va libérer la mémoire dès l'appel du put. Cela signifie que nous sommes obligés d'appeler explicitement cette méthode à chaque fois que nous souhaitons modifier notre base de données. Une répétitivité nécessaire pour optimiser la mémoire.
Enfin, voilà comment Formal nous permet de récupérer nos données :
$manager
->repository(Voiture::class)
->all()
->drop(1_000)
->take(100)
->foreach(static fn(Voiture $voiture) => doSomething($voiture));Encore une fois pour l'optimisation de la mémoire, les données retournées par le foreach sont streamed, c'est-à-dire qu'elles sont gérées une par une en mémoire.
À noter que l'on peut également utiliser des méthodes chaînées pour configurer les résultats. Ici, on souhaite éliminer les 1000 premiers résultats, puis récupérer les 100 suivants.
Il est possible d'aller plus loin avec le specification pattern comme par exemple :
use Formal\ORM\Specification\Entity;
use Innmind\Specification\Property;
use Innmind\Specification\Sign;
$manager
->repository(Voiture::class)
->matching(
Entity::of('carteGrise', Property::of(
'immatriculation',
Sign::equality,
'aa-123-bb',
)),
)
->foreach(static fn(Voiture $voiture) => doSomething($voiture));Cela permet de ne pas exposer le détail d'implémentation de votre base de données (en ne couplant pas votre code à du SQL pur par exemple), et permet donc à Formal d'être compatible à ce jour avec :
En résumé, et comme mentionné sur leur site, Formal est surtout utile pour gérer de la donnée dans des long living processes ou des applications asynchrones, de part sa gestion optimisée de la mémoire, donc n'hésitez pas à aller l'essayer !
Note
Formal utilise beaucoup les Monads, mais cet article serait trop long pour en parler, mais je conseille cette vidéo qui est une excellente introduction à ce concept.
Pour cette dernière conférence que je vous décortique, on voyage chez Yousign, et accompagné de Fabien Paitry.
Victime du succès de Yousign, Fabien a été confronté à un gros problème de performance alors que les Webhooks de son API ont rapidement été surchargés et n'ont plus été en capacité de traiter correctement les évènements reçus (ici, on parle notamment des évènements envoyés lorsqu'un document a été signé électroniquement).
Ces évènements sont envoyés dans des Queues RabbitMQ et sont consommés au fur et à mesure. Cependant, avec la montée en charge, viennent des queues contenant beaucoup trop de messages, et donc beaucoup plus de risque de faire "tomber" l'API qui devient sursollicitée :
La première solution proposée est d'adopter la Fail fast policy. Pour cela, on regarde quel est le temps de réponse habituel de nos webhooks, et on réduit au maximum le timeout selon ce temps de réponse moyen. Par exemple, Fabien a trouvé que la plupart de ses webhooks répondaient en 1 seconde, et c'est le timeout qui a été choisi et configuré dans les queues.
Ainsi, on accélère le traitement des messages tant que l'API se porte bien, et dans le cas contraire, on vient peupler la retry queue plutôt que la queue principale.
Question
Que faire dans ce cas-là ?
C'est là que Fabien nous a présenté la deuxième solution apportée : l'adoption du pattern Circuit breaker.
Ce pattern permet de bloquer les appels vers un service au-delà d'un certain seuil d'échec. Imaginez un circuit d'urgence, qui est fermé lorsque tout va bien, mais qui s'ouvre pour bloquer tous les futurs appels à un service qui ne répond plus correctement.
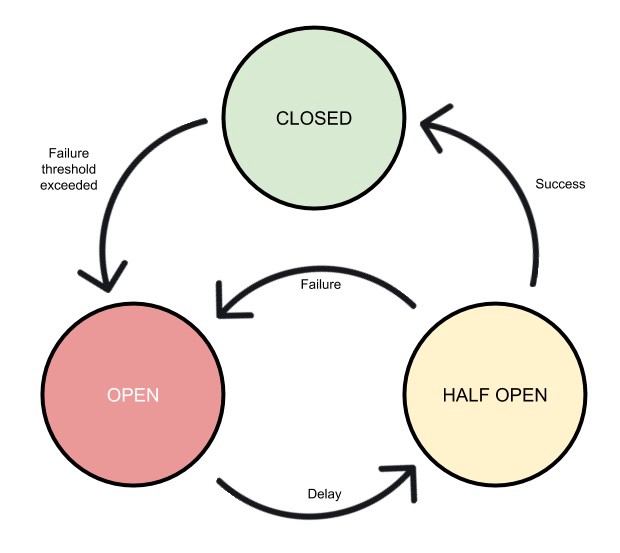
Le circuit est donc fermé par défaut, et on configure un seuil au-delà duquel on considère qu'il n'est pas normal de plus recevoir de réponse (par exemple au delà de 30% d'échec pour 50 appels).
Dans ce cas, le circuit se réveille, s'ouvre et vient court-circuiter les appels : le circuit est ouvert.
Au bout d'un certain temps (à configurer en amont), le circuit passera en half-open (semi-ouvert): on autorise à nouveau l'envoi d'un appel, pour vérifier l'état du service (à la manière d'un healthcheck).
Si la réponse est satisfaisante, on ferme le circuit, et l'application se comporte à nouveau normalement.
Si à l'inverse la réponse est toujours négative, on garde le circuit ouvert pour un certain temps.
La bonne nouvelle, c'est qu'il existe une librairie en PHP qui fait exactement ce boulot pour nous, il s'agit de Ganesha !
Et ouvrez vos chakras, car comme vous l'avez compris, ce pattern n'est pas réservé aux Webhooks et autres processus asynchrones, voyez par exemple ci-dessous comment utiliser le pattern circuit-breaker avec Ganesha et l'HTTP Client de Symfony :
use Ackintosh\Ganesha\Builder; use Ackintosh\Ganesha\GaneshaHttpClient; use Ackintosh\Ganesha\Exception\RejectedException; $ganesha = Builder::withRateStrategy() ->timeWindow(30) ->failureRateThreshold(50) ->minimumRequests(10) ->intervalToHalfOpen(5) ->adapter($adapter) ->build(); $client = HttpClient::create(); $ganeshaClient = new GaneshaHttpClient($client, $ganesha); try { $ganeshaClient->request('GET', 'http://api.example.com/awesome_resource'); } catch (RejectedException $e) { // If the circuit breaker is open, RejectedException will be thrown. }
Nous avons un GaneshaHttpClient qui vient décorer celui de Symfony, et rajouter ses fonctionnalités de circuit breaker par dessus, selon les différents seuils configurés.
C'est ultra puissant, et très simple à mettre en place.
Note
Commencez toujours par essayer de trouver des solutions de design applicatif avant de vous ruer sur l'achat de plus de ressources de calcul !
Ce forum PHP 2024 aura encore une fois été très riche en enseignements et nouvelles découvertes. Toutes ces conférences ont attisé ma curiosité d'aller plus loin dans l'apprentissage de certains concepts, même si je n'oublie pas les préceptes de notre cher Pascal Martin: il faut accepter de ne pas pouvoir tout savoir !
Et ce forum aura au moins la qualité de nous rendre humble devant l'étendue des connaissances que nous n'avons pas encore.
Mention spéciale aux conférences sur l'AutoMapper de Jolicode, ou encore le ZDD par Smaïne qui auraient mérité de figurer ici, mais n'hésitez pas à vous rendre sur la chaîne YouTube de l'AFUP pour y retrouver la captation des conférences qui devraient sortir d'ici peu.
Merci encore à l'AFUP pour ces super confs, merci à CITEO pour l'invitation à mon égard, et à la prochaine pour de futurs articles !
Auteur(s)
Arthur Jacquemin
Développeur de contenu + ou - pertinent @ ElevenLabs_🚀
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Le composant Symfony ExpressionLanguage : qu'est-ce que c'est ? Quand et comment l'utiliser ? Comment créer des expressions lors de cas plus complexes ?

Découvrez comment réaliser du typage générique en PHP : introduction et définition du concept, conseils et explications pas-à-pas de cas pratique.

Découvrez un cas d'usage d'intégration d'un CRM avec une application e-commerce, en asynchrone, avec Hubspot et RabbitMQ