CQRS, qui signifie Command Query Responsibility Segregation, est issu du CQS (Command Query Separation) introduit par Bertrand Meyer dans son ouvrage Object Oriented Software Construction. Meyer soumet le principe que les classes d'une méthode doivent être soit des queries soit des commands.
La différence entre le CQS et le CQRS résulte dans le fait que chaque object CQRS est divisé en deux objets : un pour la requête et un pour la commande.
Une commande est définie comme une méthode qui change un état, alors qu'une requête (query) ne fait que retourner une valeur.
La figure suivante montre l'implémentation basique du pattern CQRS au sein d'une application. Elle entreprend l'échange de messages sous forme de commandes et d’événements. Voyons cela de plus près.
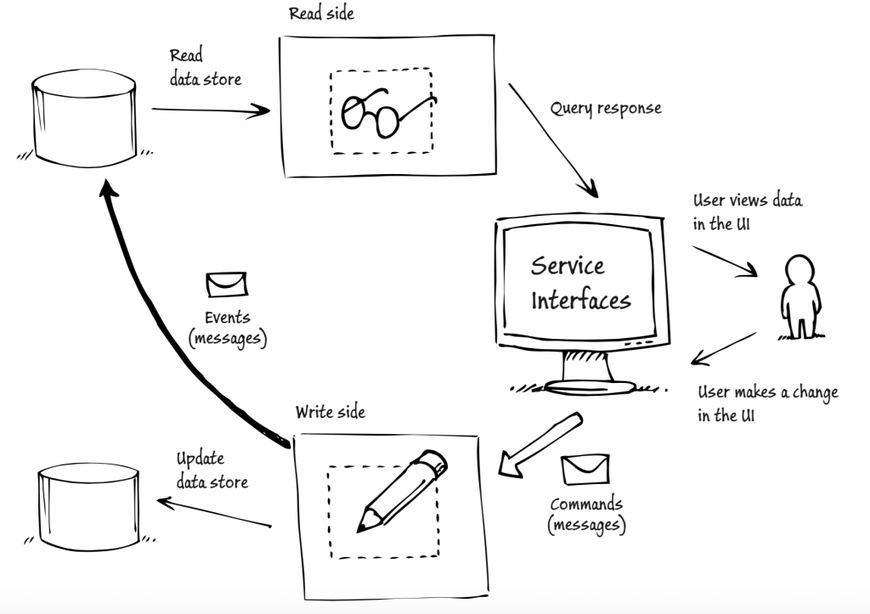 Figure 1: Exemple d'implémentation du pattern CQRS
Figure 1: Exemple d'implémentation du pattern CQRS
On voit clairement la séparation des parties lectures et écritures sur la figure précédente : l'utilisateur fait une modification sur sa page, ce qui engendre l'envoie d'une commande. Une fois cette commande terminée, un _event _est publié pour signaler qu'une modification a été apportée.
Voyons cela plus en détail.
Commands
Une commande demande à notre application de faire quelque chose. Elle se nomme toujours à l'indicatif, comme par exemple TerminateBusiness ou SendForgottenPasswordEmail. Il est très important de ne pas cantonner ses noms de commandes à des create, change, delete... et vraiment se concentrer sur les use cases (voir le document CQRS Documents en annexe pour plus d'informations).
Une commande capte l'intention de l'utilisateur. Aucun contenu de réponse n'est retourné par le serveur, car comme nous en avons discuté précédemment, seules les queries sont responsables de la récupération de données.
Queries
Utiliser différents data stores dans notre application pour la partie command et query semble être une idée plus qu'intéressante. Ainsi, comme nous l'explique très bien Udi Dahan dans son article Clarified CQRS, nous pourrions créer une base de données orientée pour l'interface utilisateur, qui reflétera ce que l'on doit afficher à notre user. On gagnera en performance et en rapidité.
Dissocier nos datastores (un pour la modification de données et un pour la lecture) ne nous oblige pas à utiliser de base de données relationnelles pour les deux par exemple. Ainsi, il serait plus judicieux d'utiliser une base de données rapide en lecture pour nos queries.
Mais si nous dissocions nos sources de données, comment les garder synchronisées? En effet, notre read data store n'est pas censé savoir qu'une commande a été envoyée! C'est là où les événements arrivent.
Events
Un événement est une notification de quelque chose qui s'est passé. Tout comme une commande, un événement doit respecter une règle de dénomination précise. En effet, le nom d'un événement doit toujours être au passé, car il faut notifier d'autres parties à l'écoute de notre événement qu'une commande a été complétée. Par exemple, UserRegistered est un nom d'événement valide.
Les événements sont traitées par un ou plusieurs consommateurs. C'est donc ces consommateurs qui sont en charge de garder la synchronisation de notre query data store.
Tout comme les commandes, les événements sont des messages. La différence avec une commande se résume à cela : une commande est caractérisée par une action qui doit se produire, contrairement à un événement qui s’est produite.
Avantages et inconvénients
Les différents avantages concernant cette ségrégation sont nombreux. En voici quelques uns :
- Scalability : Le nombre de lectures étant généralement bien plus élevé que le nombre de modification dans une application, le fait d'appliquer le modèle CQRS permet de se focaliser indépendamment sur chacun des deux enjeux. Un avantage majeur de cette scission est la scalability, qui permet une mise à l'échelle de la partie lecture différente de notre partie écrite (allouer plus de ressources, différents types de base de données).
- Flexibilité : il est facile de mettre à jour ou ajouter coté reading sans changer quoique ce soit niveau écriture. La cohérence des données n'est donc pas altérée.
L'un des principaux inconvénients est, comme le souligne l'excellent article CQRS Journey, de convaincre les membres de l'équipe que les bénéfices justifient la complexité additionnelle de cette solution.
Utilisation
Le pattern CQRS est à utiliser dans un bounded context (notion clé du Domain Driven Development), ou un composant métier de votre application. En effet, bien que ce modèle ait un impact sur votre code à beaucoup d'endroits, il ne doit pas résider au niveau le plus haut de votre application.
Event Sourcing
Ce qui est intéressant avec le CQRS est l’event sourcing. Ce dernier peut être utilisé sans l'application du modèle CQRS, mais si on utilise le CQRS, l’event sourcing devient presque une obligation.
L’event sourcing consiste à sauvegarder chaque événement qui se déroule dans une base de données et avoir ainsi une sauvegardes des faits. Dans un modèle d’event sourcing, vous ne pouvez pas supprimer ou modifier d’événement, vous ne pouvez qu’en ajouter. Ceci est bénéfique pour notre business et notre SI car nous pouvons savoir à un moment T dans quel état se trouve une commande, un client, ou autre. Egalement, la sauvegarde des événements nous permet de pouvoir reconstruire l’enchaînement de ces derniers et gagner en analyse.
L'un des exemples donné par Greg Young dans la conférence Code on the Beach, est le solde d'un compte en banque. Ce dernier peut être considéré comme une colonne dans une table, que l'on vient mettre à jour dès que l'argent est débité ou ajouté sur le compte. L'autre approche est de stocker dans notre base de données l'ensemble des transactions qui ont permis d'arriver à ce solde. Il devient donc plus facile d'être sûr que le montant indiqué est le bon, car nous gardons une trace de tous ces événements, sans pouvoir les changer.
Nous ne rentrerons pas dans les détails sur ce principe dans cet article. Cependant, un très bon approfondissement est disponible dans l'article (disponible en bas de document) CQRS Journey.
Recap
CQRS est un pattern simple, qui engendre de fantastiques possibilités. Il consiste à séparer la partie lecture et écriture de votre application, grâce à des queries et des commands.
De nombreux avantages résultent de l'utilisation, notamment en termes de flexibilité et de mise à l'échelle.
L'event sourcing complète le pattern CQRS en sauvegardant l'historique qui détermine l'état actuel de notre application. Ceci est très utile dans des domaines comme la comptabilité, car vous avez ainsi dans votre data store une suite d’événements (par exemple de transactions financières) ne pouvant être modifiés ou supprimés.
Pour approfondir le sujet
CQRS Documents, Greg Young
CQRS Journey, Dominic Betts, Julián Domínguez, Grigori Melnik, Fernando Simonazzi, Mani Subramanian
Clarified CQRS, Udi Dahan
CQRS and Event Sourcing - Code on the Beach 2014, Greg Young



