
Retour sur le Forum PHP 2024
Découvrez un résumé concis des conférences qui nous ont le plus marqué lors du Forum PHP 2024 !

Je suis actuellement Lead développeur pour un site de presse Français à très fort trafic (lemonde.fr). Au cours de mes expériences précédentes, j'ai pu développer sur plusieurs autres sites à forte volumétrie.
Quand avec seulement une dizaine de serveurs vous devez contenir des pics de trafic entre 100 000 et 300 000 visiteurs instantanés, le cache n'est plus optionnel. Il devient une véritable nécessité. Votre application peut avoir les meilleures performances, vous serez toujours limités par vos machines physiques -même si ce n'est plus vrai dans le cloud (avec un budget illimité)- le cache doit donc devenir votre ami. Avec l'expérience que j'ai pu accumuler sur le sujet et les nombreux pièges dans lesquels je suis tombé, je vais tenter de vous donner les meilleurs solutions d'utilisation des différents caches.
Vous avez souvent dû entendre dire, ou dire vous-même "vide ton cache", lors du test des fonctionnalités de votre site web. Vous devez même connaître les touches suivantes par cœur :
| Navigateurs | Raccourcis clavier |
|---|---|
| Firefox | Ctrl + F5 |
| Chrome | Ctrl + F5 ou Maj + F5 ou Ctrl + Maj + N |
| Safari | Ctrl + Alt + E |
| Internet Explorer | Ctrl + F5 |
| Opera | Ctrl + F12 |
Rassurez-vous, il y a une solution : le but de cet article est de vous permettre d'enfin apprivoiser le cache HTTP.
Le cache HTTP utilise le même principe que n'importe quel cache, il s'agit simplement d'un enregistrement clé/valeur.
Comment est choisie la clé ? Et quelle est la valeur ?
La clé est une valeur unique qui permet de reconnaître une page web, vous commencez sans doute à comprendre qu'il s'agit bien évidemment de l'url. La valeur stockée quant à elle, est le contenu de votre page dans tous les formats possibles (text, html, json, etc ...). Le cache HTTP permet beaucoup de choses que nous verrons au fur et à mesure de l'article.
Mais comment utiliser toutes ces fonctionnalités ?
Il vous suffit de regarder ce que contient une requête HTTP. En version simple, une requête contient un header et un contenu. Le contenu est ce que le navigateur affiche, le plus souvent, il s'agit de votre page html. Le header, quant à lui, contient toutes les informations essentielles de la page, la plus connue étant le "status code" permettant de savoir le statut de la page (200 OK, 404 Not Found, 500 Error), mais c'est aussi le lieu de la configuration de votre cache HTTP. De nombreux header peuvent être changés pour améliorer et configurer votre cache.
Maintenant que nous savons où nous devons configurer notre cache,
Que pouvons-nous configurer ?
D'abord, activons le cache pour notre page. Pour cela, nous devons ajouter le header.
Cache-Control: public
Il existe d'autres paramètres pour ce header que je vous invite à retrouver sur https://fr.wikipedia.org/wiki/Cache-Control, un des plus utilisés est le
Cache-Control: no-store
permettant de désactiver le cache sur la page. Nous pouvons désormais configurer le temps de cache de la page, c'est ce que l'on appelle le TTL de la page. Pour cela, le header à changer est le suivant :
max-age: 300
300 étant un temps de cache donné en seconde. Vous pouvez trouvez dans certaines documentations disponibles un header très ressemblant :
s-max-age: 300
Il a la même utilité que le header max-age mais permet d'être utilisé sur un proxy (varnish par exemple) et donc avec un TTL différent pour le CDN et le proxy. Vous pouvez aussi choisir une date d'expiration ce qui permet d'être encore plus précis avec le cache, le header est simple :
Expires: Thu, 25 Feb 2016 12:00:00 GMT
Avec ces trois header, vous pouvez déjà utiliser le cache avec une bonne précision, en gérant vos TTL et expirations, vous pouvez faire vivre vos pages et les laisser se décacher toutes seules.
Mais comment les décacher à volonté ?
Le cache HTTP a une fonctionnalité très intéressante permettant de demander au serveur de calculer s'il doit renvoyer une nouvelle page. Pour l'utiliser, il suffit de remplir un nouveau header lors de la génération de la page.
Last-Modified: Wed, 25 Feb 2015 12:00:00 GMT
Le client (votre navigateur) envoie quant à lui un header dans sa requête au serveur . Si le serveur renvoie une date plus récente que celle du client alors le client prend la nouvelle page. Sinon, il garde la page dans le cache. Cela permet aussi de gérer la réponse 304 qui permet au serveur de n'envoyer que le header de la réponse (soit un contenu vide) qui réduit la bande passante utilisée par le serveur. Pour cela, le serveur doit avoir l'intelligence de lire le header Last-modified et dans le cas ou la nouvelle date générée n'est pas plus récente, il peut renvoyer une requête HTTP 304 permettant au client de garder son cache. Il existe un autre header ayant le même principe, il s'agit du header Etag, qui se configure avec un 'string' généré par le serveur qui change selon le contenu de la page.
Etag: home560
Attention, le calcul de l'etag doit être très réfléchi puisqu'il régit le temps de cache de la page, il doit donc être calculé avec les données dynamiques de la page. Comme expliqué dans le premier chapitre, la clé du cache HTTP est l'url de la page. Cela peut être gênant si votre page est dynamique selon l'utilisateur car l'url sera la même, mais le contenu sera différent. Il faut donc cacher plusieurs contenus pour une url. Heureusement, Tim Berners-Le, l'inventeur du protocole HTTP a prévu le cas en ajoutant le header :
Vary: Cookie User-agent
Comme son nom l'indique, il permet de faire varier le cache en utilisant un autre header, par exemple 'User-agent' qui permet de stocker pour une url toutes les pages pour chaque user-agent (exemple page mobile, page desktop). Le Cookie permet de stocker une page par cookie (donc par utilisateur). Nous venons de faire un tour plutôt complet des configurations possibles pour le cache HTTP, mais il est aussi possible d'ajouter ses propres header. Avant d'avancer sur ce sujet, nous allons réfléchir à l'architecture du cache HTTP.
Vous savez configurer votre cache comme un professionnel.
Mais où placer votre cache ?
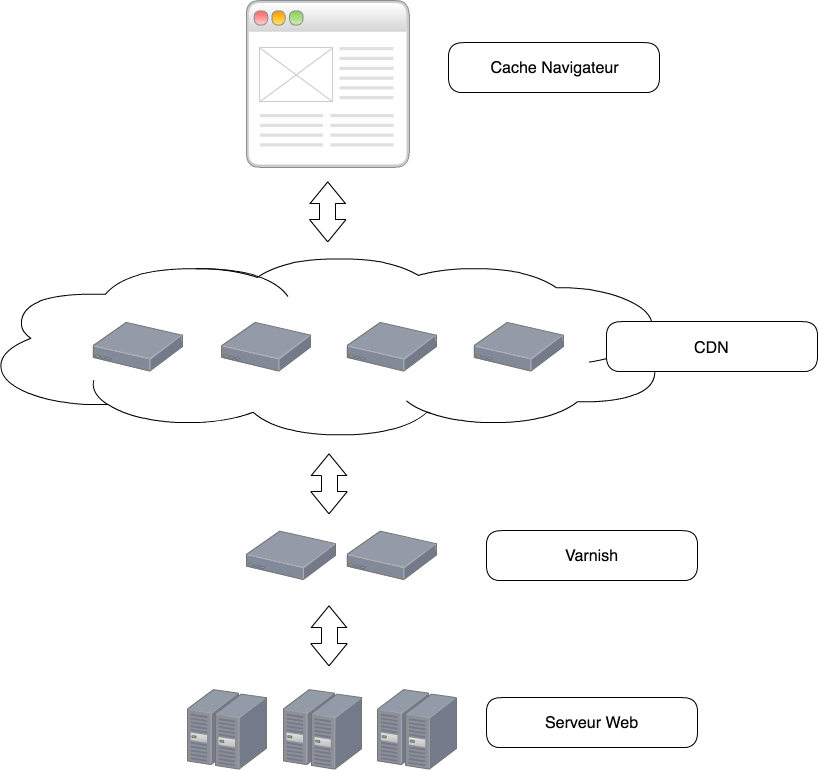
Le cache HTTP peut être utilisé à plusieurs endroits dans votre architecture, chaque endroit a des spécificités et permet une amélioration des performances.
C'est le cache HTTP le plus proche de votre utilisateur : ce qui lui permet d'être très rapide. Le seul souci est qu'il est lié avec l'utilisateur, il peut donc être vide assez souvent, exemple lors de la première connexion. Il peut aussi être vidé par l'utilisateur ou même désactivé. La résilience de ce cache ne vous est donc pas imputée, ce dernier doit donc être couplé avec un autre cache HTTP.
Le Content Delivery Network est un réseau d'ordinateurs permettant de servir du contenu (https://fr.wikipedia.org/wiki/Content_delivery_network). Il est externe à l'architecture et sa spécialité est la géolocalisation, il permet donc à un utilisateur d'aller sur le CDN le plus proche. Vous en avez surement déjà utilisé un quand vous utilisez un tag js, exemple jquery, angular etc ..., et que vous utilisez l'url fournie plutôt que le fichier téléchargé. L'avantage principal du CDN est d'avoir de nombreux serveurs à travers le monde et de vous permettre de ne pas recevoir l'ensemble du trafic du site sur vos serveurs. Si vous avez déjà travaillé pour un site à fort trafic, le CDN est le meilleur moyen de ne pas maintenir 10 000 serveurs pour votre application. Le coût d'un CDN est souvent lié à la bande passante, il est donc important de cacher seulement ce dont vous avez besoin et d'utiliser le plus de 304 possible.
Il agit comme le CDN et ce dernier appartient à l'architecture. Il s'agit souvent de serveurs que vous maintenez, il demande beaucoup de RAM (le stockage y est fait). Le varnish ou autre technologie de cache permet des configurations plus fines qu'un CDN et surtout permet d'utiliser ses propres header. Il permet aussi d'utiliser les ESI que nous verrons dans le prochain chapitre. (Akamai l'inventeur des ESI est un CDN)
Le web serveur aussi permet d'utiliser le cache HTTP, on l'utilise généralement pour le cache des assets (js, css, images, etc ...). Comme le varnish, son avantage est d'être configurable très finement.
L'avantage du cache HTTP est que son utilisation est très simple, et que la plupart des frameworks web mettent en place des interfaces simples pour utiliser ce dernier. Malgré un nombre de fonctionnalités très important, nous avons toujours besoin de plus, c'est pour cela que lors d'un projet sur un site à fort trafic, on place deux header varnish personnalisés qui peuvent aider.
X-Varnish-Catalog: |home|345|567|
Il s'agit d'un header qui référence votre page, soit par terme (home, page, etc ...), soit par id d'objet.
Mais pourquoi faire ?
Parce que cela vous permet de facilement trouver toutes les pages stockées dans varnish et qui référencent un objet particulier, si vous pouvez les trouver, vous pouvez les supprimer, et donc générer un cache. Il faut pour cela configurer varnish pour réaliser un ban d'une url. Voici un petit code simple à mettre en place :
# Ban - Catalogue decache
#
# How to ban all objects referencing <my_tag> in the X-Cache-Varnish-Catalog header
# curl -X BAN http://<varnish_hostname>/uncache/<my_tag>
# Object header ex. : X-Cache-Varnish-Catalog: |1235|9756|546|687|37436543|<my_tag>|region-centre|
if (req.method == "BAN") {
if (!client.ip ~ invalidators) {
return (synth(405, "Ban not allowed"));
}
if (req.url ~ "^/uncache/") {
ban("obj.http.X-Cache-Varnish-Catalog ~ |" + regsub(req.url, "^/uncache/([-0-9a-zA-Z]+)$", "") + "|");
return (synth(200, "Banned with " + req.url));
}
return (synth(200, "Nothing to ban"));
} X-Varnish-Grace: 300
Comme le max-age, vous devez lui donner un temps en seconde. Ce petit header permet de gagner encore plus en performance. Il dit à votre varnish le temps acceptable pour renvoyer un cache même après l'expiration du max-age.
Pour mieux comprendre, voici un exemple : Prenons la page /home qui à pour header :
Cache-control: public
max-age: 300
X-varnish-grace: 600
Imaginons que varnish a la page dans son cache, si un utilisateur arrive à la 299ème seconde, varnish renvoie directement le cache.
Mais que se passe t-il à la 301ème seconde ?
S'il n'y avait pas le Grace, varnish serait obligé d'appeler directement le serveur pour obtenir la réponse à renvoyer à l'utilisateur. Mais avec le Grace, varnish va renvoyer son cache et demander au serveur un nouveau contenu, ce qui permet de ne pas avoir de temps de latence pour l'utilisateur.
Et maintenant à la 601ème seconde ?
Facile, votre page est expiré la requête arrive directement sur votre serveur. Voici la configuration pour varnish :
sub vcl_backend_response {
# Happens after we have read the response headers from the backend.
#
# Here you clean the response headers, removing silly Set-Cookie headers
# and other mistakes your backend does.
# Serve stale version only if object is cacheable
if (beresp.ttl > 0s) {
set beresp.grace = 1h;
}
# Objects with ttl expired but with keep time left may be used to issue conditional (If-Modified-Since / If-None-Match) requests to the backend to refresh them
#set beresp.keep = 10s;
# Custom headers to give backends more flexibility to manage varnish cache
if (beresp.http.X-Cache-Varnish-Maxage) {
set beresp.ttl = std.duration(beresp.http.X-Cache-Varnish-Maxage + "s", 3600s);
}
if (beresp.http.X-Cache-Varnish-Grace && beresp.ttl > 0s) {
set beresp.grace = std.duration(beresp.http.X-Cache-Varnish-Grace + "s", 3600s);
}
}Vous êtes désormais un expert dans l'utilisation du cache HTTP, il ne reste plus qu'une chose à comprendre : les ESI. Edge Side Include (ESI) permet d'utiliser toute la puissance de varnish. Comme indiqué plus haut, cette technologie fut inventée par Akamai, l'un des plus célèbres CDN.
À quoi ça sert ?
Le problème le plus simple est le suivant. Sur chacune des pages, vous avez un bloc de pages qui est toujours le même mais vous devez le changer souvent. La solution est de décacher l'ensemble des pages contenant le bloc, cela pourra très vite devenir embarrassant car vos serveurs vont alors être trop souvent sollicités. Les ESI servent dans cette situation. Il s'agit seulement d'une page avec son cache propre que l'on peut intégrer dans une autre via une balise HTML.
//home.html <html> <body> <esi url='block.html'/> Test </body> </html>
Varnish va reconnaître l'utilisation d'un ESI et va donc cacher deux objets, l'un pour la page complète avec les informations de cache de la page et l'un pour ESI avec d'autres informations de cache. Vous pouvez alors décacher seulement l'ESI et varnish va mettre à jour un seul objet (une seule demande au serveur), l'utilisateur a tout de même toutes les pages mises à jour.
Pour plus d'informations, je vous invite à aller voir un ancien article , qui explique une implémentation pour Symfony. Vous pouvez aussi retrouver une présentation sur le cache HTTP et Symfony ici.
Auteur(s)
Jonathan Jalouzot
Lead développeur au @lemondefr, mes technologies sont le symfony depuis 2009, le nodejs, l'angularjs, rabbitMq etc ... J'adore les médias et aimerai continuer dans ce secteur plein de surprise. Vous pouvez me retrouver sur les réseaux sociaux: Twitter: @captainjojo42 Instagram: @captainjojo42 Linkedin: https://fr.linkedin.com/in/jonathanjalouzot Github: https://github.com/captainjojo
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Découvrez un résumé concis des conférences qui nous ont le plus marqué lors du Forum PHP 2024 !

L'Anchor positioning API est arrivée en CSS depuis quelques mois. Expérimentale et uniquement disponible à ce jour pour les navigateurs basés sur Chromium, elle est tout de même très intéressante pour lier des éléments entre eux et répondre en CSS à des problématiques qui ne pouvaient se résoudre qu'en JavaScript.

Le composant Symfony ExpressionLanguage : qu'est-ce que c'est ? Quand et comment l'utiliser ? Comment créer des expressions lors de cas plus complexes ?