
Automatiser la vérification du commit
Automatiser la vérification du commit avec commitlint

Je vais vous expliquer aujourd'hui dans cet article un cas concret de mise en place d'une architecture orientée événements réalisé pour l'un de nos clients du Studio Eleven Labs. Vous découvrirez dans cet article, ce qu'est concrètement une architecture orientée événements (ou event driven architecture) et comment la mettre en place. Suivez le guide !
L'architecture orientée événements (Event Driven Architecture) utilise des événements pour déclencher et communiquer entre des services découplés. Elle est courante dans les applications modernes construites avec des microservices. Un événement correspond à un changement d'état, ou une mise à jour : commande payée, ou utilisateur créé, par exemple. Les événements transmettent un état à un instant T (le numéro de transaction, le montant et le numéro de commande).
Les architectures orientées événements comportent trois composants clés : les émetteurs (producers), les transmetteurs (routers) et les consommateurs (consumers). Un producer publie un événement sur le routeur, qui filtre et transmet les événements aux consumers. Les services émetteurs et les services consommateurs sont découplés, ce qui leur permet d'être modifiés et déployés de manière indépendante.
Découplage : en découplant vos services, ils ne connaissent que le routeur d'événements, ils ne dépendent pas directement les uns des autres. Cela signifie que vos services sont interopérables : mais si un service tombe en panne, les autres continueront de fonctionner. Le découplage simplifie le processus d'ajout, de mise à jour ou de suppression de producers et de consumers, permettant des ajustements rapides pour répondre aux nouveaux besoins. Cela permet également de mettre en place et de respecter les principes SOLID, plus particulièrement le Single Responsability principle.
La maintenabilité : vous n'avez pas besoin d'écrire du code custom pour gérer les événements, le routeur d'événements filtrera et transmettra automatiquement les événements aux consumers. Le routeur s'occupe également de la coordination entre les producers et consumers. Ainsi, chaque consumer possède son scope précis. Différentes équipes peuvent maintenir chaque consumer indépendamment, sur des stacks et timelines différentes.
Immutabilité : une fois créés, les événements ne peuvent pas être modifiés, ils peuvent donc être partagés avec plusieurs services sans risque qu'un service modifie ou supprime des informations que d'autres services consommeraient ensuite.
Scalabilité : un événement déclenche plusieurs actions en parallèle chez différents consumers, améliorant ainsi les performances. Chaque consumer est indépendant, potentiellement sur une infrastructure différente des autres, et peut scale sans impacter le reste.
Réponses en temps quasi-réel : les événements sont consommés au fur et à mesure qu'ils se produisent, fournissant des réponses en temps quasi-réel aux interactions importantes avec votre platefrome. Cette agilité garantit que les clients reçoivent toujours les informations au plus vite sans pour autant être bloqués dans leur expérience utilisateur.
L'architecture orientée événements peut utiliser le modèle de pub/sub ou le modèle de event streaming.
Pub/sub : lorsqu'un événement est publié, le router va le communiquer à tous les consumers qui sont abonnés à cet événement. Si un nouveau consumer s'abonne à un événement, il n'a pas accès aux événements passés. C'est l'exemple que nous allons voir plus bas.
Event streaming : les événements sont enregistrés dans un journal dans l'ordre chronologique. Un client peut lire n'importe quelle partie du flux à n'importe quel moment. Cela signifie aussi qu'un client peut s'abonner à tout moment et avoir accès aux événements passés.
Voyons un cas concret en PHP/Symfony avec RabbitMQ. Imaginons une architecture avec plusieurs microservices qui ont besoin de communiquer entre eux dans le cas de validation d'une commande. Le service Purchase valide un paiement et publie le message associé. Le service Mailer envoie un email de confirmation de commande. Le service Catalog réduit le stock disponible pour les produits concernés.
Reprenons ensemble le fonctionnement du modèle AMQP 0-9-1 (vous pouvez trouver la documentation ici) :
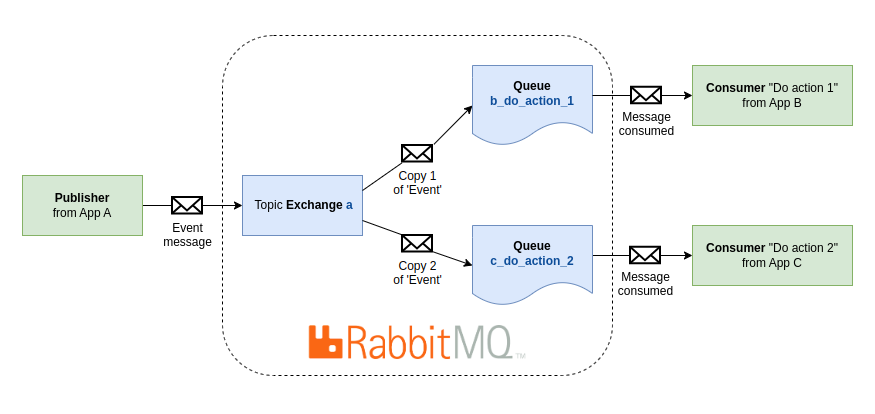
Les messages sont publiés sur des exchanges, voyez ça comme une boîte aux lettres. Les exchanges distribuent ensuite des copies des messages aux queues à l'aide des bindings. Ensuite, les consumers récupèrent les messages des queues à la demande.
Nous allons utiliser Swarrot Bundle pour la suite de l'exemple. Vous pouvez lire un article sur son fonctionnement ici. Vous pouvez, bien sûr, utiliser le composant Messenger de Symfony aussi.
Je vous propose de convenir ensemble de quelques conventions à respecter pour mettre en place un Event Driven Design.
Chaque application a son propre exchange, et elle ne peut publier que dans son exchange. Cela nous permet d'assurer une séparation des responsabilités de chaque application pour respecter les principes SOLID. Nous allons utiliser des exchanges de type topic pour permettre l'utilisation des wildcards dans les routing keys.
Le message, c'est ce qui va être envoyé depuis un publisher à un consumer. Par convention, nos messages seront au format JSON.
La donnée principale sera contenue dans la propriété data du message, et toute information secondaire sera dans une propriété meta.
Un message est associé à une routing key.
Dans l'architecture orientée événement, elle va correspondre à l'événement qui a eu lieu.
Pour assurer l'unicité d'une routing key, et étant donné que le nom d'une entité peut figurer dans plusieurs microservices, nous allons nommer nos routing keys de la façon suivante : app.entity.{id}.event.
Par exemple purchase.order.42.paid voudrait dire que dans l'application Purchase, l'objet Order avec l'identifiant 42 vient de passer en état "payé".
Notez que les événements doivent représenter des événements métiers en premier, bien que parfois les événements du cycle de vie de vos entités puissent aussi être utiles (session.exam.42.created).
Chaque object qui sera communiqué via Rabbitmq aura son publisher, par exemple l'entité Order aura son OrderPublisher. Chaque événement publié correspondra à une fonction qui porte le nom de l'événement. Le publisher pourra être appelé depuis un Event Subscriber Doctrine par exemple. Attention, cependant, les publishers doivent être appelés après l'enregistrement du changement d'état dans le service émetteur (la sauvegarde du statut paid de la commande dans cet exemple). Même si le consumer est asynchrone, RabbitMQ est très rapide, et le consumer pourrait recevoir le message avant enregistrement en base de données (ou avant erreur d'enregistrement potentielle).
// class OrderPublisher
public function paid(Order $order, bool $isAnonymous): void
{
$this->publisher->publish(
self::MESSAGE_TYPE,
$this->serializer->serialize(
[
'data' => $order,
'meta' => [
'isAnonymous' => $isAnonymous,
],
],
'json',
SerializationContext::create()->setGroups('publish-order')
),
['content_type' => 'application/json'],
['routing_key' => sprintf('purchase.order.%d.paid', $business->getId())]
);
}Comme vous pouvez voir, nous avons également un groupe de sérialization spécifique pour nos publishers.
Cette fonction doit publier un contenu comme ceci :
{ "data": { "id": 42, "amount": 124.80, "payment": { "identifier": "XXX", // ... }, // ... }, "meta": { "isAnonymous": false } }
Un consumer va dépiler des messages qui se trouvent dans une queue.
La queue s'abonne à un événement (subscribe) via les bindings à l'exchange et la routing key.
Elle va suivre le schéma app_action, par exemple mailer_send_order_confirmation nous indique que l'application Mailer va envoyer un email de confirmation.
Le consumer va porter le nom de l'action à réaliser, sans mentionner l'événement qui va déclencher cette action, par exemple, SendOrderConfirmationConsumer.
Nous partons du principe que l'application doit réaliser une action indépendamment de ce qui la déclenche.
Ainsi, notre configuration de queue ressemblera à ceci :
queues: mailer_send_order_confirmation: durable: true bindings: - exchange: "purchase" # the application that published the message routing_key: "purchase.order.*.paid" # named after the published event
Avec ces règles simples, nous pouvons facilement implémenter l'architecture orientée événements. Nous devons placer les événements au centre de notre refléxion pour construire les échanges de notre plateforme autour de ceux-ci.
Au sein du Studio Eleven Labs, nous utilisons cette architecture comme moyen privilégié de communiquer entre microservices pour tous les avantages mentionnés plus haut.
Auteur(s)
Marie Minasyan
Astronaute Raccoon @ ElevenLabs_🚀 De retour dans la Galaxie.
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Automatiser la vérification du commit avec commitlint

Découvrez un résumé concis des conférences qui nous ont le plus marqué lors du Forum PHP 2024 !

Dans le domaine de la data, la qualité de la donnée est primordiale. Pour s'en assurer, plusieurs moyens existent, et nous allons nous attarder dans cet article sur l'un d'entre eux : tester unitairement avec Pytest.