
Apache Iceberg pour une architecture lakehouse sur AWS
Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Mastra AI est un framework Typescript orienté développement d'outils IA. Que ce soit pour créer des Agents, des Workflow (à la n8n), mettre en place un serveur MCP ou encore créer les Tools pour articuler tout cela, Mastra AI met à disposition tout un tas d'API pour vous assister dans la création de ces outils.
En l'occurence, nous nous servirons de certaines APIs de Mastra pour nous aider à faire du RAG (Retrieval-Augmented Generation). Si vous ne savez pas en quoi cela consiste, nous allon y venir dans la prochaine partie !
Mais tout d'abord, qu'allons-nous faire exactement ? Notre cas d'usage est très simple, prenons le Blog d'Eleven Labs, sur lequel nous nous trouvons actuellement. Nous aimerions rendre la recherche d'article plus intelligent et plus pertinente. Quand un utilisateur fait une recherche, que ce soit par mot-clé, par problème renontré ou même sous la forme d'une simple question, il faudrait que le Blog réponde par une liste des articles et tutoriels les plus pertinents, et avec des petits résumés personnalisés expliquant en quoi chaque article correspond au problème de l'utilisateur.
Nous allons donc créer un Agent IA, qui va se charger de récupérer la requête de l'utilisateur, passer par un RAG pour récupérer le contenu le plus adapté à cette requête, puis utiliser un LLM classique pour formater correctement la réponse ! Et vous pourrez voir que rien qu'avec cela, on va couvrir une bonne partie de tout ce qui est possible de créer avec Mastra !
Et avant de commencer, comme promis, voici un petit point concernant ce fameux RAG.
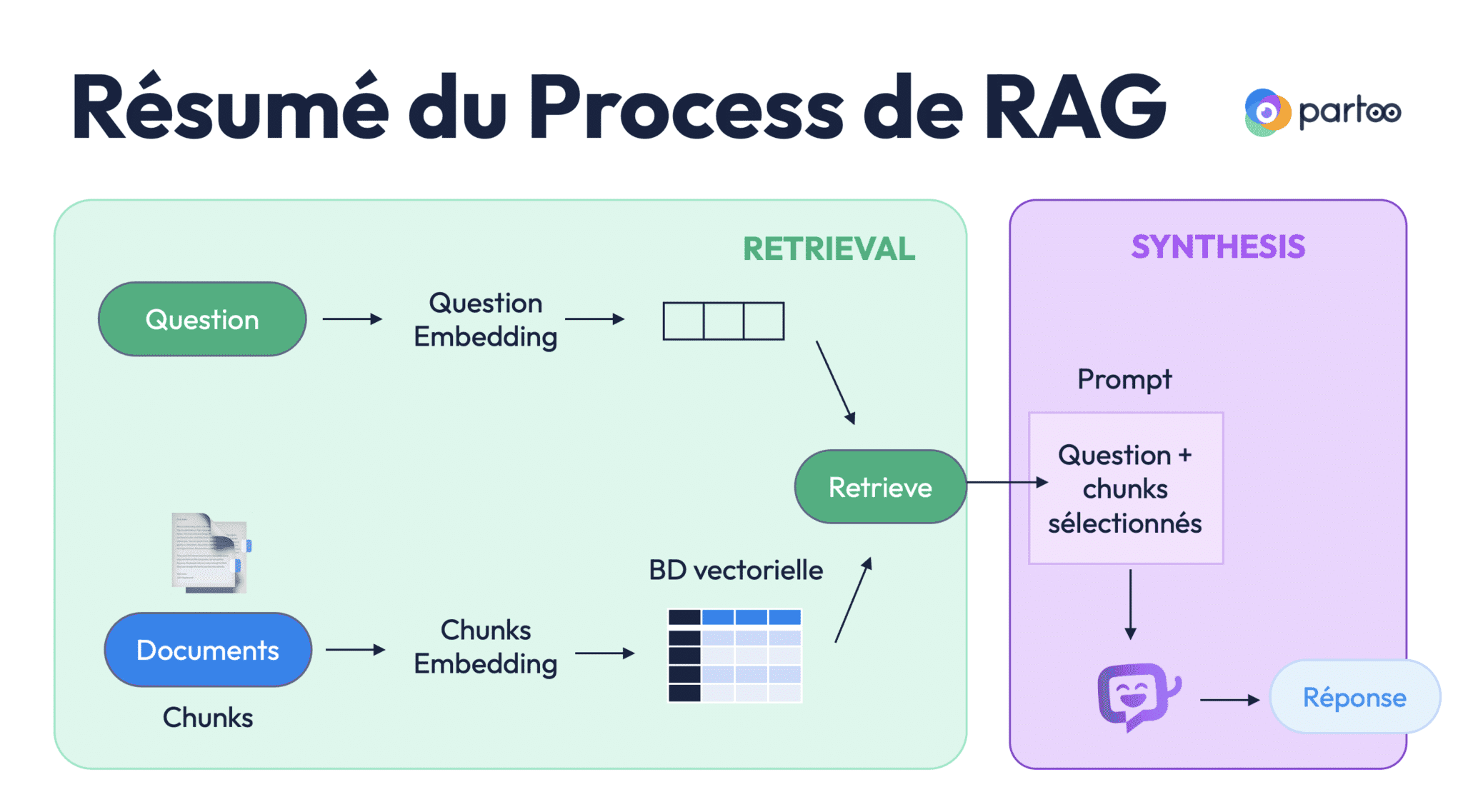
Pour réaliser notre projet vous l'aurez deviné, c'est un LLM qui génèrera une réponse à notre utilisateur. Mais pour être pertinent, il aura besoin de contexte, autrement comment deviner quels articles proposer ? De même, on va éviter de filer tout le texte compilé de tous nos articles dans le prompt de notre modèle, cela ferait beaucoup trop de contexte et donc trop de complexité pour le LLM de faire le tri et de proposer une réponse précise (en plus de coûter très cher en tokens d'input), et cela favoriserait grandement le phénomène d'hallucination.
Donc non, on va simplement stocker tout le contenu de nos articles en base de données, puis trouver un moyen de déduire lesquels sont intéressants selon la question de l'utilisateur.
Question
... LIKE '%keyword%' ..
Ce serait très rudimentaire, mais surtout on manquerait plein de résultats pour 3 raisons:
Et c'est là que les bases de données vectorielles entrent en jeu. Rassurez-vous, j'ai toujours été une bille en maths, et j'ai malgré tout compris plutôt facilement le concept du RAG.
Pourquoi des vecteurs ? Et comment les générer ? En fait, il est beaucoup plus simple de stocker des valeurs numériques en base de données car contrairement au texte, on peut effectuer des calculs dessus. Et ce sont justement des calculs qui vont nous aider à récupérer les bonnes valeurs (nos articles donc, au préalable transformés en vecteur).
Et pas de panique, pas besoin de générer ces vecteurs soi-même, on va utiliser un embedding model. Il s'agit d'un modèle IA dont le but est de convertir un texte en un vecteur de nombres, en se basant justement sur de la similarité sémantique, ainsi 2 phrases qui partagent un sens commun partageront également le même espace vectoriel.
Il existe plein de modèles d'embeddings, plus ou moins performants (et plus ou moins coûteux).
Voici le workflow du RAG:
Cette recherche de similarité peut utiliser différentes méthodes mathématiques qui peuvent être appliquées aux vecteurs (cosinus, distance euclidienne...). On appelle cela la similarité sémantique. Cette fois, on recherche vraiment des résultats selon le sens du texte plutôt qu'en comparant les mots.
Par exemple prenons ces 2 phrases:
Elles sont peu similaires au niveau des mots utilisés, mais l'idée exprimée est sensiblement la même. Il y a donc fort à parier qu'une fois vectorisées, elles aient une valeur numérique très proche. Et donc lors d'une recherche par similarité, on devrait facilement les retrouver.
Pareil ici, on n'aura pas à implémenter ces calculs nous-même. Mastra AI nous fournit toutes les APIs nécessaires pour transformer nos documents en vecteurs, les stocker en base, puis récupérer les vecteurs pertinents en fonction d'une requête.
Maintenant que vous comprenez le principe du RAG, on va pouvoir se lancer dans notre projet, en commençant par présenter les outils utilisés.
Auteur(s)
Arthur Jacquemin
Développeur de contenu + ou - pertinent @ ElevenLabs_🚀
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Plongez dans le monde des AST et découvrez comment cette structure de données fondamentale révolutionne le développement moderne.

Retour sur ma première journée de conférences autour de l'IA au Grand Rex à Paris