{kind=link}

Apache Iceberg pour une architecture lakehouse sur AWS
Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Les 25 et 26 octobre s'est tenue l'édition 2018 du Forum PHP. Les astronautes étaient encore une fois présents sur place. Voici les retours des conférences qui les ont marqués.
Reprenez le contrôle de @postgresql grâce à @PommProject #forumphp pic.twitter.com/s7twFk4rKf
— Mathieu MARCHOIS (@mmarchois) 25 octobre 2018
Mickal Paris est venu nous parler de POMM, un outil qui va nous aider à "reprendre le contrôle de PostgreSQL". Aujourd'hui, dans nos applications, nous utilisons un ORM pour communiquer avec nos bases de données. C'est utile pour faire abstraction du langage SQL.
Seulement, l’utilisation d’un ORM met le métier au centre du développement. POMM est une alternative au ORM. Il se définit comme un gestionnaire de modèle objet qui force à recentrer la base de données au coeur du métier. Le but est de laisser de côté l'aspect code, et de se concentrer sur le SGBD (en l'occurrence PostgreSQL, donc) afin de mieux l'appréhender et d'augmenter ses performances. Un des inconvénients de POMM par rapport à un ORM est le manque d’interopérabilité avec différents SGBDR, car il est disponible uniquement avec PostgreSQL.
POMM se décompose en trois briques principales : Foundation, ModelManager et Cli.
Foundation est la brique centrale composée de sessions et de clients. C’est avec cette brique que vous ferez vos query_manager, prepared_query, observer, converter, notifier, inspector.
Le ModelManager est une brique extension de la première, apportant de la modélisation objet par rapport à la base de données.
Quant à la brique CLI, elle va nous faciliter la vie en générant les différents objets. Des commandes d'inspection sont également disponibles pour éviter d'ouvrir une console psql.
Vous pouvez utiliser POMM dans vos projets Symfony. Voici le lien du dépot GitHub: POMM project - bundle. Et si vous voulez en savoir plus, voici le lien de site du projet POMM project
Voici le lien de la vidéo de la présentation de Mickal Paris sur POMM : afup.org - Reprenez le contrôle de PostgreSQL grâce à POMM
Présentation disponible: https://t.co/h4lYEeZkbt #MySQL #forumphp
— Olivier DASINI (@freshdaz) 29 octobre 2018
Olivier Dasini est venu nous parler de MySQL 8.0 et de ses nouveautés. ALors il y a eu beaucoup de nouvelles fonctionnalités sur MySQL 8.8. Mais les plus notables sont : -l'apparition de NoSQL documentaire -l’API développeur -les window functions
Et oui, maintenant, depuis MySQL vous pouvez faire du NoSQL orienté document. Ici je ne vais pas revenir sur le NoSQL donc je vais directement vous parler de l’API.
L'intégration du NoSQL dans MySQL 8.0 va vous permettre de centraliser vos données dans un seul SGBD. De plus avec la nouvelle APi dev vous pouvez mêler query SQL et NoSQL ce qui vous permettra d'optimiser le nombre de requêtes vers votre SGBD. Mais aussi plusieurs nouvelles Windows Functions sont apparues pour permettre de prendre en charge le NoSQL.
En plus de toutes ces nouvelles fonctionnalités MySQL 8.0 a subi un petit lifting de performances comme le montre ce graphique :
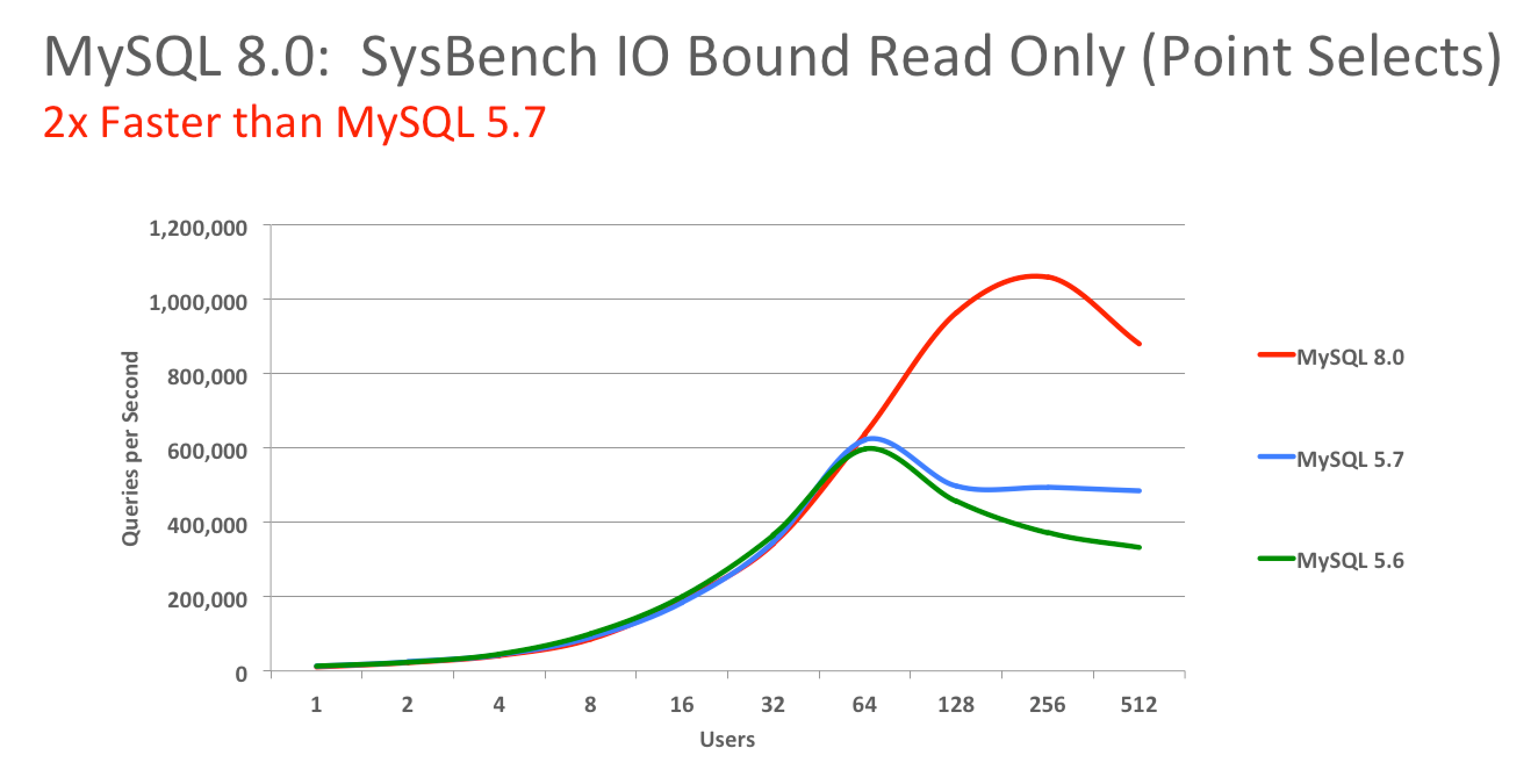
Voici le lien des slides et de la vidéo de la présentation d'Olivier Dasini sur MySQL 8.0 : afup.org - MySQL 8.0: Quoi de neuf ?
"Le retard c'est la différence entre le rêve et la réalité"
— Jérémy Villard (@jevillard) 26 octobre 2018
Cette conférence est quasi un one-man-show 🤣 Merci à @f_leguedois au #forumphp @afup @GroupeSmile pic.twitter.com/6nELF2YkRk
Frédéric Leguédois est venu nous parler des estimations dans la gestion de projet. En plus d’avoir fait un one man show surprenant, Frédéric Leguédois nous a démontré rapidement que les estimations étaient une fausse bonne pratique dans la gestion de projet. Avec un argumentaire plus que préparé et une conviction sans bornes Frédéric Leguédois à sans doute fait changer d’avis la quasi-totalité de son auditoire du PHP Forum.
Je ne vais pas reprendre tous ses arguments car je vous conseille d'assister à une de ses conférences, mais le premier qui m’a marqué est celui-ci : “Un chef de projet reçoit un cahier des charge, il va le lire une fois, deux fois et à la troisième fois comme par magie il donne une estimation : 3 mois avec 8 personnes. Mais comment a-t-il fait ?”.
Les suivants sont identiques et confortent cette incohérence des estimations. Par exemple sur un projet de deux ans, et avec la meilleure estimation possible, si vous faite un bilan un an après le démarrage du projet vous allez voir que les estimations de l’année dernière n’ont plus rien à voir et que le premier planning prévisionnel à eu x versions pour pouvoir retrouver une pseudo corrélation avec la réalité du projet.
Concrètement, il défend le fait que les estimations ne sont pas une bonne pratique Agile. Si on regarde le Framework “Agile” le plus utilisé et populaire, Scrum, on peut constater qu’il ne s'inscrit pas vraiment dans la philosophie Agile. Une des valeurs de l’Agilité est La collaboration avec les clients plus que la négociation contractuelle et faire des estimation va simplement permettre d’entrer dans une phase de négociation entre Dev Team et client, l'Agilité est rompue.
De mémoire cela fait neuf an que Frédéric Leguédois travaille sans estimations et ses clients sont contents car il n’y a tout simplement pas de retards.
Merci à tous pour vos retours et vos questions ! <3
— Thomas Jarrand (@Tom32i) 25 octobre 2018
Pour (re)tester la démo et lire un IRM sur votre téléphone c'est ici : https://t.co/4aQSGHAX6t
Le code est open-sourcé ici : https://t.co/TA7knR7qlN#forumphp #EtOuiJamy
En travaillant à la conception d’un jeu de type « serious game » pour l’université de Bordeaux et la Harvard Medical School, Thomas Jarrand a été confronté à des problématiques intéressantes telles que :
Le projet sur lequel Thomas travaillait consistait à afficher des IRM du cerveau dans les navigateurs. Après avoir appris comment repérer une lésion par le biais du jeu, on présente des images à l’utilisateur qui va dire s’il voit ou non une lésion dans le cerveau. Le but étant de « crowdsourcer » cette reconnaissance et d’essayer par la suite de l’automatiser.
Thomas a donc dû trouver un moyen d’afficher ces IRM qui sont enregistrés au format .nii (pour Nifti) dans le navigateur. Ce format est de type binaire et assez volumineux.
Après avoir lu les specs (nifti-1) du format Nifti il a pu trouver le détails des données octet par octet : les 352 premiers octets constituent le Header (348 pour le header et 4 pour l’extension), ce header donne du détail sur la structure du fichier, le reste constitue le détail de l’image en voxel.

Thomas Jarrand nous a aussi fait un rappel sur comment sont affichées les images sur nos écrans et comment en partant de cela avec les specs il avait pu afficher l’IRM.
Concrètement, chaque pixel de nos écrans est constitué de 3 couleurs (rouge, vert, bleu), l’intensité de chacune de ces couleurs peut être géré indépendamment pour fournir n’importe quel mélange des 3 couleurs primaires. Cette intensité peut être représentée par une valeur allant de 0 à 255 soit une valeur sur un octet (8 bits).
C’est ce qu’il se passait dans le format Nifti ou une section du binaire peut être lu 3 octets par 3 octets pour avoir la teinte de chaque pixel les uns après les autres :
Après chaque série de 3 octets on passe donc au pixel suivant.
Ce travail a permis à Thomas de comprendre comment il est possible d'optimiser certaines informations par le biais du binaire en définissant une spec adaptée.
« Une fois que l’on sait comment est écrite l’information on peut tout faire, le binaire supporte tout et est supporté partout »
Pour finir, il nous a présenté quelques limites du binaire, comme la rigidité une fois mis en place. Bref une bonne piqûre de rappel sur les tailles et le fonctionnement des formats d’images sur l’ordinateur et de tout ce qu’il est possible de faire avec un fichier binaire bien documenté !
N’ayant pas encore le lien de son talk, voici le git de son projet : https://github.com/Tom32i/talk-binary-brain
Ou encore la démo navigateur : https://talk.tom32i.fr/binary-brain/demo/
Et on reprend avec @beoneself pour un retour sur des programmes de bug bounty et comment combattre les failles de sécurité #forumphp pic.twitter.com/Xqtm0PQtD7
— Darkmira (@Darkmira1) 25 octobre 2018
Xavier Leune (directeur technique adjoint chez CCMBenchmark, et ex-president de l’AFUP) est venu pour nous faire un retour d’expérience sur la sécurité des applications de manière générale, le coût moyen de la première année, mais aussi une démonstration de quelques failles, inconnues dans son entreprise avant de les subir.
La présentation de Xavier à commencé par l’exposition de failles de sécurité sur un blog de démo, je vous laisserai regarder le talk pour en voir la plupart. Certaines étaient d’un niveau élevé. L’idée que Xavier souhaitait nous faire retenir était que « quelqu’un pensera toujours à un moyen que vous ne connaissez pas, que vous n’avez peut-être jamais vu »
Je ne citerai qu’un des exemples : Xavier après avoir « sécurisé » son application pour une faille HTTP, nous a montré que dans le manuel « curl » on pouvait utiliser un autre protocole à la place d’HTTP qui était Gopher. Il a donc re-effectué sa requête avec Gopher plutot qu’HTTP, une nouvelle faille apparaissait permettant d’envoyer un mail depuis le compte du site attaqué.
Après cette démo impressionnante, Xavier nous a un peu parlé de culture de la sécurité. Aujourd’hui, peu de gens sécurisent leur application correctement. On fait des tests unitaires pour les bugs mais on a pas de « tests unitaires de sécurité ». On peut mandater des pentesteurs pour faire des test d’intrusions ou lancer des bug bounties.
Le bug bounty c’est quoi ? C’est proposer à des experts en sécurité d’essayer de casser votre site et de rémunérer la rémontée de l’information en fonction de son importance.
Lors de l’ouverture de leur site et après avoir proposé des bug bounties sur leur site, Xavier et son entreprise recevaient 25 rapports en 2 jours et plus de 50 en 8 jours.
La mise en place de ces bug bounties peut prendre un temps considérable,. I faut bien échanger avec le client et les développeurs pour éviter l’apparition de messages gênant sur le site en production par exemple.
La sécurité est par ailleurs assez coûteuse. Xavier parlait d’un budget moyen de 10 000€ la première année.
À notre époque il n’est plus possible de cacher des fuites de données sous le tapis. Il est donc important de les éviter. Il faut donc apprendre à mettre son orgueil de développeur de côté et accepter que la sécurité est un métier, et que l’on ne produit pas du code sécurisé d’office.
Je vous laisse le constater par vous même avec sa démonstration que vous pourrez retrouver ici : https://afup.org/talks/2741-securite-bug-bounty-php
Comment fonctionne la cryptographie par @julienPauli @sensiolabs #forumphp pic.twitter.com/ENENNfPFAE
— Mathieu MARCHOIS (@mmarchois) 25 octobre 2018
Julien Pauli est venu nous faire un rappel des « bases » de la cryptographie. Ces bases sont en réalité en pratique assez complexes, je vous conseille donc grandement de voir le talk de Julien, qui donne de très bonne explications passionnées dessus.
Il n’existe qu’un seul moyen de coder une information de manière sécurisée à 100% : l’OTP (One Time Password) de Vernam. Je vous laisse chercher le détail de cet algorithme sur Internet, beaucoup seront capable de vous l’expliquer mieux que moi, mais de manière résumée on a :
un message en clair qu’on encrypte en utilisant une clef aléatoire pour obtenir un message crypté caché.
Pour que cela soit possible, 4 conditions doivent être réunies : la clef doit être totalement aléatoire la clef doit être cryptée la clef doit faire AU MOINS la taille de ce que l’on cherche à crypter la clef ne doit SURTOUT pas être utilisée une deuxième fois

(L’image ci-dessus représente bien ce qui pose problème lors de la réutilisation d’une clef)
Ces conditions sont malheureusement très difficiles à respecter dans le cadre de l’informatique. Concrètement, si on veut chiffrer un élément de 26Mo il faudra une clef de 26Mo. Comment faire alors pour chiffrer la navigation réseau qui va être très très longue ? On peut utiliser LFSR : Linear Feedback Shift Register, qui permet de rendre une clef finie virtuellement infinie. Cela peut potentiellement introduire un autre problème : on abandonne l’aspect aléatoire à cause du fonctionnement électronique. On ne peut pas abandonner l’aléatoire car cela fait partie des 4 conditions pour une cryptographie sûre.
Certains algorithmes et structures électroniques ont donc été mis en place pour essayer de palier à ces problèmes, la plupart ont fini par être brisés.
Je vous laisse en regarder la démonstration dans le talk. Il est conseillé d’avoir des notions d’électronique pour suivre une bonne moitié de la présentation, la première partie est cependant accessible à tout le monde :
https://afup.org/talks/2693-comment-fonctionne-la-cryptographie
Une édition 2018 encore à la hauteur de ce qu'on pouvait en attendre, des confs quali et une super ambiance sur tout le salon ! On se donne rendez-vous en 2019 ;)
Auteur(s)
Nicolas Grévin
Ingénieur DevOps SRE spécialisé en conteneurisation, Kubernetes, CI/CD, cloud, Infrastructure as Code et outillage. Engagé dans la Green IT et développeur passionné.
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Plongez dans le monde des AST et découvrez comment cette structure de données fondamentale révolutionne le développement moderne.

Retour sur les deux journées de conférences pour la SymfonyLive Paris 2025 à Paris.