
Symfony Live 2025 : les 20 ans du framework !
Retour sur les deux journées de conférences pour la SymfonyLive Paris 2025 à Paris.

Dans cet article, nous allons nous plonger dans l'intégration d'un CRM (Customer Relationship Management) avec une application e-commerce.
Nous vous donnerons des exemples concrets sur lesquels nous avons travaillé au sein du Studio Eleven Labs.
Nous utilisons un CRM SaaS (Software as a Service) doté de fonctionnalités qui jouent un rôle central dans la gestion efficace des relations clients. Ce CRM offre aussi la possibilité d'utiliser une API et des webhooks (qui permettent de recevoir des notifications en temps réel) qui vont nous permettre de connecter ce système à nos autres applications.
En parallèle de ce CRM se trouve une plateforme e-commerce personnalisée, qui représente le cœur de notre activité : nous souhaitons les connecter.
Bien entendu, ces principes d'intégration pourraient s'appliquer également à divers systèmes externes, comme des ERP (Enterprise Resource Planning), et différents CRMs comme Salesforce et HubSpot (Restez à l'affût, car nous publierons bientôt des articles détaillés sur les spécificités d'intégration avec ces CRMs). Mais pour les besoins de notre exemple dans cet article, nous allons prendre en considération seulement HubSpot.
Pour réaliser cette intégration, nous allons adopter une approche basée sur le concept d'Event Driven Design, où des événements (events) se déclenchent des deux côtés de l'équation, et nous utiliserons l'outil RabbitMQ pour faciliter cette synchronisation bidirectionnelle.
Je vous invite à consulter cet article de Marie qui explore plus en profondeur ce concept d'Event Driven que nous utilisons de manière générale pour communiquer entre nos applications, que ce soient des microservices ou avec des applications externes comme des CRMs.
Par exemple, des événements peuvent provenir de notre plateforme e-commerce (comme business_created ou purchase_updated) et aussi du CRM (comme company_edited). Les événements se manifestent des deux côtés.
flowchart LR
CRM --event company_created--> E_COMMERCE["E-Commerce"] --event user_created--> CRM
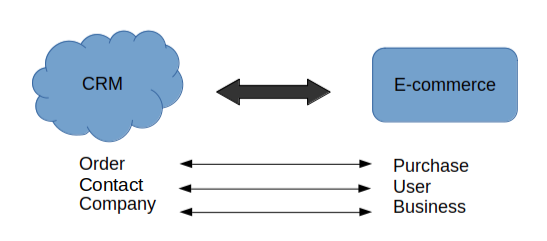
Lorsque l'on synchronise un CRM avec une application e-commerce, il faut d'abord bien définir les objets métiers à synchroniser et il est essentiel de prendre en compte des correspondances entre ces objets des deux systèmes qui peuvent avoir des formats différents.
Par exemple, un contact côté CRM équivaut à un user côté e-commerce, une company à un business, et un order à un purchase.
Dans notre exemple de synchronisation depuis Hubspot vers le e-commerce, le CRM peut déclencher un webhook pour notifier un changement spécifique de statut de Company ou Contact côté CRM.
La première solution simple à laquelle on pense serait de réceptionner ce webhook directement sur notre plateforme e-commerce puis de faire ensuite des appels GET synchrones à l'API d'Hubspot pour récupérer les données avant de les enregistrer.
Mais cela nécessiterait de faire plusieurs appels API pour récupérer toutes les informations à synchroniser : Company et tous les Contacts liés par exemple. Ces nombreux appels API rendent complètement dépendante notre application e-commerce qui se retrouve couplée au CRM.
Imaginons aussi qu'un problème survienne au moment de la synchronisation des Contacts de la Company en question, à cause d'un souci d'accès à l'API HubSpot ou la base de données de notre e-commerce par exemple, nous aurions une Company enregistrée sans aucun Contact, et une erreur dans les logs. Il faudrait re-GET les informations des Contacts liés à cette Company.
Ainsi, lors de notre implémentation, nous avons opté pour une approche plus adaptée basée sur de l'Event Driven Design (lien vers l'article de Marie), asynchrone, avec une politique de "retry" pour gérer au mieux les possibles erreurs, le tout orchestré par un microservice dédié à cette synchronisation.
Tout d'abord, pour gérer ce processus nous avons mis en place une application dédiée, seule responsable de gérer cette synchronisation.
C'est donc cette application qui va être capable de recevoir les différents événements provenant :
Ensuite pour chaque événement reçu, ce service va récupérer les données dans l'application source qui a émis l'événement, puis transformer et mapper ces données pour ensuite mettre à jour ces informations dans l'autre application de destination.
Nous avons décidé d'intégrer cette fonctionnalité de manière asynchrone afin de maintenir l'indépendance entre nos applications CRM et e-commerce.
Aussi, dans notre contexte, nous n'avions pas besoin d'un retour synchrone visible sur les interfaces utilisateurs des applications qui ferait apparaître en temps réel un statut de synchronisation.
Également, cette implémentation Event Driven Design asynchrone offre une grande résilience. Lorsqu'un événement est publié, il est stocké dans une file d'attente : queue RabbitMQ dans notre cas. Si, pour une raison quelconque, la synchronisation échoue, les événements restent dans la file d'attente, prêts à être traités à nouveau. Cela signifie que les erreurs temporaires ou les pannes de système n'impactent pas la synchronisation des données. De plus, la possibilité de mettre en place des mécanismes de "retry" automatique garantit que les données seront finalement synchronisées avec succès, même en cas de problèmes temporaires.
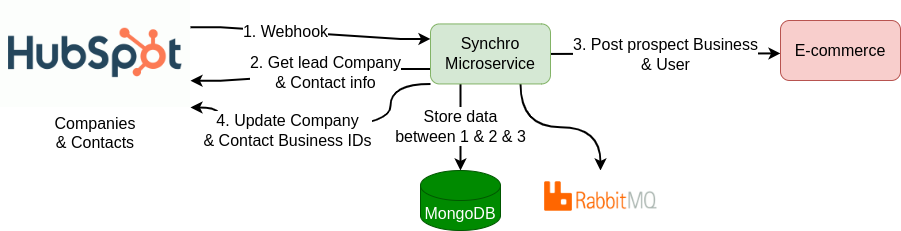
Sur le schéma ci-dessus, voici les différentes étapes de la synchronisation Hubspot vers e-commerce :
Company, stockée sur MongoDB (1)Company et des Contacts associés vers HubSpot (2)Company et Contact dans RabbitMQ (3)Company et Contacts tels que définis côté e-commerce dans RabbitMQ (4)Company & Contacts côté Hubspot (4)Enfin, la synchronisation s'effectue dans l'autre sens (bidirectionnelle) : de la platforme e-commerce vers HubSpot avec le schéma ci-dessous.
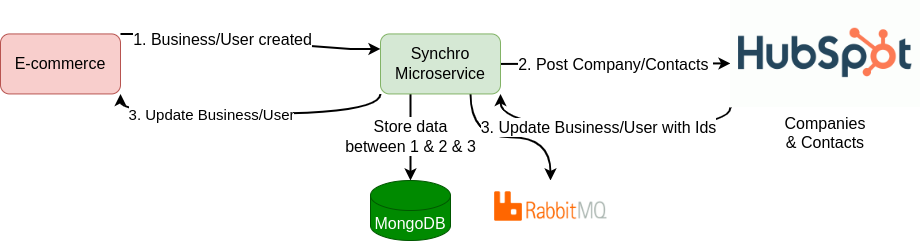
Company et Contacts tels que définis côté e-commerce dans RabbitMQ (4)Company & Contacts côté Hubspot (4)On en avait parlé dans un article précédent : nous pouvons facilement configurer une stratégie de "retry" sur chaque queue et consumer RabbitMQ, avec la possiblité de configurer des durées et timeout de retry différents par process.
Cette stratégie de "retry" permise par RabbitMQ est un point important dans notre implémentation de processus de synchronisation pour être résilient aux erreurs et parce que nous dépendons d'un CRM en service externe SaaS que nous ne maîtrisons pas. Ainsi si ce service est temporairement indisponible, nous laissons nos consumers "retry" jusqu'à ce que le service soit fonctionnel à nouveau.
Dans notre exemple illustré sur les schémas ci-dessus, nous faisons en sorte que chaque étape soit implémentée dans un consumer dédié avec un stockage "intermédiaire" en base de données. Cela rend donc chaque étape indépendante, bénéficiant de son propre "retry".
Aussi, même pour une simple réception de webhook venant du CRM, on a choisi de stocker et re-publier cet événement directement dans notre broker RabbitMQ, pour être sûr de ne pas dépendre d'autres appels APIs, qui sont ainsi découplé dans d'autres étapes qui ont leur propre consumer et mécanisme de "retry".
Note
Il est aussi intéressant de porter attention aux types d'erreurs possibles dans nos consumers pour ne "retry" que certains types. Par exemple, il est important de s'assurer que l'on "retry" dans le cas d'erreur réseau ou d'erreur serveur "500" retournée par le CRM SaaS externe. À l'inverse, les erreurs "400 Bad Request" peuvent être ignorées et non "retry" puisqu'après "retry" les données envoyées à l'API seront toujours invalides.
Cette stratégie permet une synchronisation presque en temps réel. Bien que cela soit asynchrone, la latence est généralement très faible. Les événements sont traités rapidement, ce qui signifie que les mises à jour des données dans votre CRM ou e-commerce sont quasi-instantanées.
Dans notre cas, la synchronisation presque en temps réel est une approche qui privilégie la réactivité, l'expérience utilisateur, le suivi en temps réel des activités et la réduction de la latence.
À l'inverse, une synchronisation par lots (batching) une fois par jour est moins réactive, peut générer des problèmes de performance et entraîne des retards dans la mise à jour des données qui peuvent avoir des impacts fonctionnels.
Le choix entre ces deux approches dépend des besoins spécifiques de votre entreprise et de vos objectifs en matière de gestion des données.
Lors de l'implémentation d'un tel processus de synchronisation, on pense forcément à gérer tous les cas de futures modifications du côté de l'application source à répliquer vers la plateforme de destination.
Mais il ne faut pas non plus négliger une problématique qui n'interviendra qu'une seule fois, lors de la mise en production de ce processus : l'initialisation des données du côté de l'application de destination, pour prendre en compte les données déjà existantes du côté de l'application source.
Par exemple, il s'agit de créer tous les users historiques du e-commerce du côté du CRM lorsque celui-ci est nouvellement ajouté à notre stack.
Si nous avions choisi une approche de synchronisation en batch une fois par jour par exemple, ce processus aurait géré de la même façon les données déjà existantes au préalable et les données modifiées ensuite : tous les jours, on copie simplement toutes les données de la source vers la destination.
Mais dans notre cas, avec cette approche Event Driven asynchrone "presque temps réel", l'initialisation des données requiert une implémentation un peu différente.
Pour autant, nous n'avons pas envie d'implémenter deux processus de synchronisation complets, dupliqués en termes de fonctionnalités mais différents dans l'implémentation, pour gérer l'initialisation et la synchronisation en "temps réel" après initialisation.
Ainsi pour initialiser les données dans le CRM nouvellement ajouté, nous avons choisi de mettre en place un script d'initialisation qui :
user, business, purchase)De cette façon, nous tirons parti du processus de synchronisation déjà mis en place plutôt que de dupliquer pour l'initialisation. Aussi nous bénéficions de la même résilience grâce au mécanisme de "retry".
Par contre, avec cette approche, vous vous retrouvez avec des centaines de milliers de messages publiés dans vos queues de synchronisation dès l'exécution du script d'initialisation. Cela peut causer ces problèmes :
C'est pour cela que nous ajustons notre script pour gérer par lots (batching) cette phase d'initialisation :
Voici certains avantages que nous avons notés lors de cette initialisation en batch :
Pour synchroniser les données de votre système vers un nouveau CRM, comprendre en profondeur le CRM que vous allez intégrer est une étape essentielle. Avant de vous lancer dans le développement, assurez-vous de bien analyser le CRM cible, testez sa connectivité API, et familiarisez-vous avec le processus de configuration des applications, ainsi que la gestion des identifiants (credentials) qui donnent accès à l'API depuis un système externe. Assurez-vous également que ce CRM supporte les webhooks dont vous aurez besoin pour mettre en place une approche Event Driven. Cette préparation minutieuse vous permettra d'éviter des erreurs coûteuses et de garantir une intégration fluide.
Lors de la mise en place de votre intégration, il est essentiel de s'assurer d'un modèle de données cohérent entre le CRM et la plateforme e-commerce. Voici comment procéder de manière méthodique :
Nous avons ainsi mis en avant notre expérience au sein du Studio Eleven Labs au sujet de l'intégration d'un CRM avec une application e-commerce, basée sur une approche Event Driven, asynchrone et quasi "temps" réel.
Vous aurez compris l'importance de mettre en place un processus résilient aux erreurs, ce qui est permis par le "retry", mais aussi de soigner toutes les étapes de synchronisation, y compris la migration initiale des données historiques.
Également, gardez bien en tête l'importance de comprendre en profondeur le CRM à intégrer, de préparer minutieusement l'approche d'intégration, et de veiller à un modèle de données cohérent entre les systèmes pour une intégration réussie et fluide.
Auteur(s)
Younes Diouri
Youyou aime le PHP !
Charles-Eric Gorron
Software Solution Architect, Team Leader & Studio Director @ Eleven Labs
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Retour sur les deux journées de conférences pour la SymfonyLive Paris 2025 à Paris.

Découvrez un résumé concis des conférences qui nous ont le plus marqué lors du Forum PHP 2024 !

Le composant Symfony ExpressionLanguage : qu'est-ce que c'est ? Quand et comment l'utiliser ? Comment créer des expressions lors de cas plus complexes ?